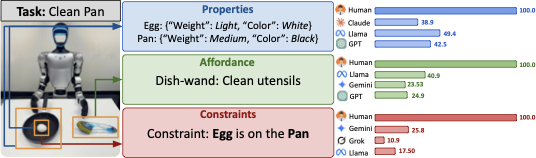
Vision-Language Models (VLMs) are increasingly pivotal for generalist robot manipulation, enabling tasks such as physical reasoning, policy generation, and failure detection. However, their proficiency in these high-level applications often assumes a deep understanding of low-level physical prerequisites, a capability that is largely unverified. To perform actions reliably, robots must comprehend intrinsic object properties (e.g., material, weight), action affordances (e.g., graspable, stackable), and physical constraints (e.g., stability, reachability, or an object's state like being closed). Despite their ubiquitous use in manipulation, we argue that off-the-shelf VLMs may lack this granular, physically-grounded understanding, as these specific prerequisites are often overlooked in their pre-training. Addressing this critical gap, we introduce PAC Bench, a comprehensive benchmark designed to systematically evaluate VLM comprehension of these core Properties, Affordances, and Constraints (PAC) from a task executability perspective. PAC Bench features a diverse dataset with over 30,000 annotations, comprising 673 real-world images (115 object classes, 15 property types, 1–3 affordances defined per class), 100 real-world humanoid-view scenarios and 120 unique simulated constraint scenarios across four tasks. Our evaluations reveal significant gaps in the ability of VLMs to grasp fundamental physical concepts, underscoring their current limitations for reliable robot manipulation and pointing to key areas that require targeted research. PAC Bench also serves as a standardized benchmark for rigorously evaluating VLM physical reasoning and guiding the development of more robust and physically grounded models for robotic manipulation.
Data Exploration
Explore representative samples from the four datasets comprising PAC Bench. Each dataset provides unique perspectives and scenarios for evaluating foundation models' understanding of properties, affordances, and constraints in robotic manipulation.
Constraint Images Dataset
Simulated scenarios designed to test understanding of physical constraints like impossible placement, stability, and reachability.
Impossible Placement
Support/Occlusion Issues
Reachability Issues
Stability Constraints
Humanoid Robot Dataset
Real-world captures from Unitree G1 humanoid robot perspective for authentic constraint scenarios.
← Scroll horizontally to view more samples →
Open Images Dataset
Diverse real-world images for property and affordance evaluation across 115 object classes.
← Scroll horizontally to view more samples →
RoboCasa Objects Dataset
Multi-angle views of household objects (24 perspectives per object) for comprehensive property evaluation. Scroll horizontally to see camera rotation through different angles.
Cheese Block
0° azimuth
45° azimuth
90° azimuth
135° azimuth
180° azimuth
225° azimuth
270° azimuth
315° azimuth
← Scroll horizontally to see camera rotation →
Donut
0° azimuth
45° azimuth
90° azimuth
135° azimuth
180° azimuth
225° azimuth
270° azimuth
315° azimuth
← Scroll horizontally to see camera rotation →
Baguette
0° azimuth
45° azimuth
90° azimuth
135° azimuth
180° azimuth
225° azimuth
270° azimuth
315° azimuth
← Scroll horizontally to see camera rotation →
Each object is captured from 24 different angles (3 elevations × 8 azimuth rotations) to provide comprehensive visual coverage for property understanding evaluation. The horizontal sliders above show the 8 azimuth angles at elevation 0°, demonstrating how the camera rotates around each object.
Dataset Overview
PAC Bench evaluates foundation models' understanding of three fundamental components crucial for robotic manipulation: Properties (intrinsic object characteristics like material, weight), Affordances (action possibilities like graspable, stackable), and Constraints (physical limitations like stability, reachability). Our benchmark features over 30,000 annotations across 673 real-world images, 100 humanoid-view scenarios, and 120 simulated constraint scenarios. This comprehensive evaluation reveals significant gaps in VLMs' physical reasoning capabilities, highlighting critical areas for improvement in robotics applications.
Experiments and Results
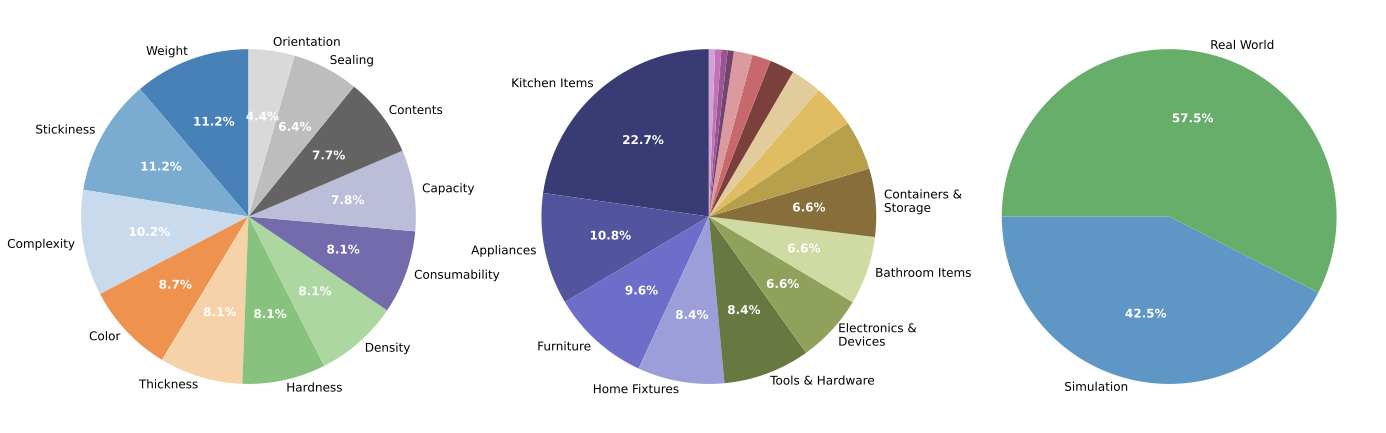
Distribution of annotations in PAC Bench across three dimensions: (Left) physical properties annotated in the dataset, showing the relative frequency of each property; (Center) affordance categories, with slices below 5% omitted for clarity; (Right) constraint domains, contrasting simulation (blue shades) and real-world (green shades) scenarios.
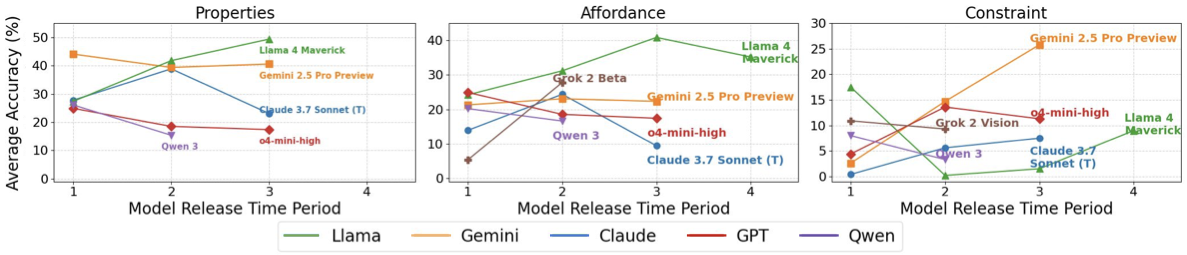
Comparative PAC understanding profiles of selected VLMs across different model generations. The diverse performance signatures suggest varied developmental trajectories in acquiring physical common sense. Our evaluation reveals significant gaps in current VLMs's ability to understand fundamental physical concepts required for reliable robot manipulation.
Detailed Performance Results
Property Understanding Accuracy (%)
Model
Open Images
Humanoid
Avg
P1
P2
P3
P4
P5
P6
P1
P2
P3
P4
P5
P6
Claude 3.5 Sonnet
0.0
31.9
0.0
0.0
2.7
42.3
50.2
28.9
50.7
52.7
19.4
55.2
27.8
Claude 3.7 Sonnet
20.2
23.5
32.6
36.7
66.4
37.0
47.8
30.3
48.3
55.7
13.2
55.7
38.9
Gemini 2.0 Flash 001
19.7
35.3
40.8
58.0
56.1
43.9
55.2
39.8
40.3
46.8
38.2
54.7
44.1
GPT-4.1
13.8
29.0
4.4
25.9
91.0
27.8
51.2
55.7
43.3
58.2
43.8
64.2
42.4
Llama 4 Maverick
36.2
34.9
37.6
47.0
90.0
14.6
43.8
77.1
59.2
57.7
40.3
54.2
49.4
Properties P1–P6: Color, Contents, Weight, Density, Sealing, Hardness. Bold values indicate best performance in each category.
Constraint Understanding Accuracy (%)
Model
Simulation
Real World
Avg
Impossible Place
Occlusion
Stability
Reachability
Humanoid
Claude 3.5 Sonnet
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
1.8
0.0
3.7
0.4
Gemini 2.5 Pro P
10.0
20.0
10.0
90.0
30.0
60.0
0.0
40.0
0.0
30.0
0.0
20.0
11.3
18.8
9.4
25.8
GPT-4.1
0.0
0.0
0.0
50.0
70.0
50.0
0.0
0.0
0.0
0.0
0.0
0.0
11.3
13.2
9.4
13.6
GPT-4.1 Mini
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
18.8
24.5
22.6
4.4
Llama 3.2 11B Vision I
20.0
10.0
0.0
30.0
30.0
20.0
20.0
20.0
20.0
10.0
30.0
0.0
0.0
1.8
0.0
17.5
Constraint understanding across four simulated domains (Impossible Placement, Occlusion, Stability, Reachability) and real-world humanoid scenarios. Bold values indicate best performance.
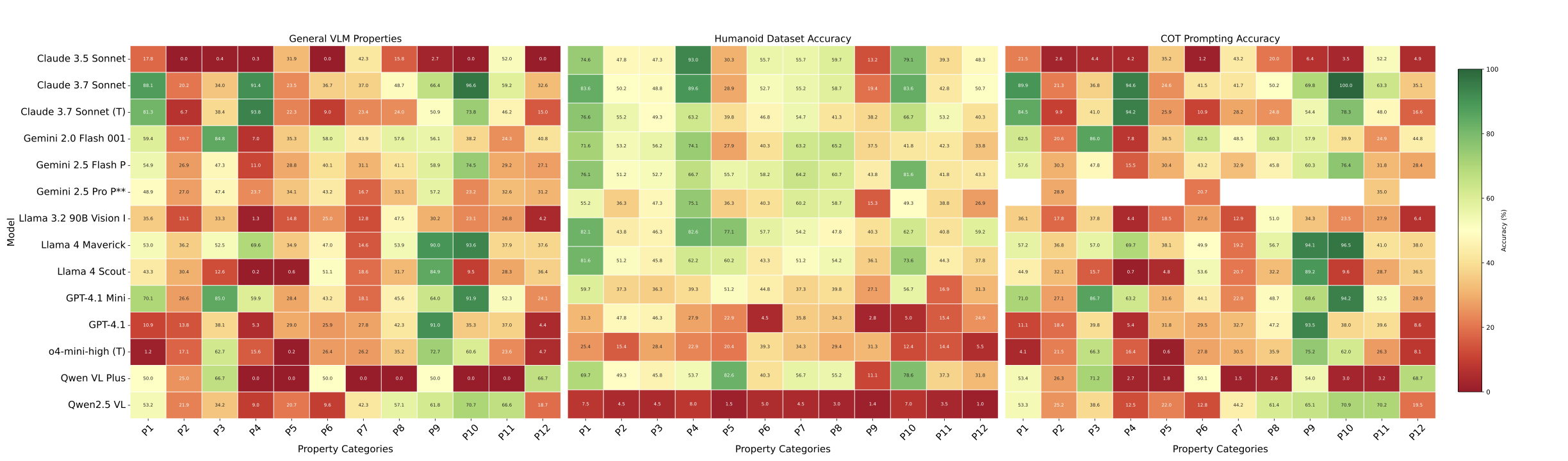
Comprehensive heatmap visualization showing property understanding accuracy across all evaluated VLMs and property types. The color intensity represents performance levels, revealing significant performance variations across different physical properties and models.
Comprehensive Affordance Recognition: Identifying ALL Correct Affordances (%)
Model
A1
A2
A3
A4
A5
A6
A7
A8
A9
A10
A11
A12
A13
A14
A15
A16
A17
A18
Claude 3.5 Sonnet
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
Claude 3.7 Sonnet
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
Gemini 2.0 Flash 001
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
GPT-4.1
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
20.0
0.0
0.0
0.0
0.0
0.0
0.0
Llama 4 Scout
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
4.5
0.0
0.0
0.0
0.0
0.0
Qwen 2.5 VL
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
11.1
0.0
Critical Finding: When required to identify ALL correct affordances (not just one), performance drops to near-zero across all models and categories, with only isolated exceptions like GPT-4.1 (20.0% on Home Fixtures) and Qwen 2.5 VL (11.1% on Tools & Hardware). This reveals that VLMs can identify primary affordances but lack comprehensive functional understanding.
Complete 12-Property Understanding Results (%)
Model
P1 Capacity
P2 Color
P3 Complexity
P4 Consumability
P5 Contents
P6 Density
P7 Hardness
P8 Orientation
P9 Sealing
P10 Stickiness
P11 Thickness
P12 Weight
Claude 3.5 Sonnet
17.8
0.0
0.4
0.3
31.9
0.0
42.3
15.8
2.7
0.0
52.0
0.0
Claude 3.7 Sonnet
88.1
20.2
34.0
91.4
23.5
36.7
37.0
48.7
66.4
96.6
59.2
32.6
Gemini 2.0 Flash 001
59.4
19.7
84.8
7.0
35.3
58.0
43.9
57.6
56.1
38.2
24.3
40.8
Complete property evaluation across all 12 property types shows significant variation in model capabilities. Claude 3.7 Sonnet excels at Capacity (88.1%) and Consumability (91.4%), while Gemini 2.0 Flash shows strength in Complexity understanding (84.8%).
 PAC Bench: Do Foundation Models Understand
PAC Bench: Do Foundation Models Understand